Cleaning the text means to remove special characters, numbers and multiple empty spaces from the text.
Add a new script frame, click copy text button and paste the contents into the frame.
There is no output from this script.
Before Cleaning
The text that appears below shows numbers, special characters and extra spaces. The items to pay attention to are: review 73, 78 and 79. Originally these had extra spaces, numbers and special characters.
Add a new script frame, click copy text button and paste the contents into the frame.
The output shows the dataset before it is cleaned.
After cleaning
Add a new script frame, click copy text button and paste the contents into the frame.
The output shows that numbers, special characters and extra space have been removed.
Stop Words
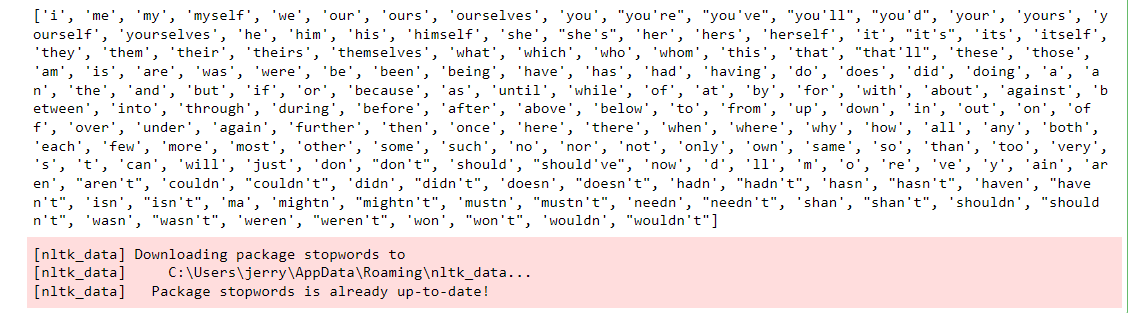
The stopwords are a list of words that are very very common but don’t provide useful information for most text analysis procedures. While it is helpful to understand the structure of sentence, it does not help you understand the semantics of the sentences themselves.1
Here’s the code to generate a list of most commonly used stop words.
Add a new script frame, click copy text button and paste the contents into the frame.
Your output should look like:
Stopwords script
The following script shows you how this function works. I made a new Python project and put the file into a dictionary format.
Start a new Python project then click copy text button and paste the contents into the frame. Save it and call it "stopWords" and run it.
Your output should look like:
Python gives us with a number of data structures such as:
lists []
tuples ()
sets {}
dictionaries { :}
They all are used to store and organize the data in an efficient manner.
Let's modify our list with tuples. Make the first sentence read "The Executive summary was incomplete. It was lacking financial information."
Modify line 5, the tuple about the mission statement. Make it read "In my opinion, The mission statement was dreadfull."
Save it and run it. You should see that the stop words were removed.
If you want to see more than the first lines of the print(test), change the line to the following: print (test.head(20))
Day 4: Sentiment Analysis with natural language tool kit (NLTK)
Sentiment Analysis is a technique to extract emotions from textual data.
We are trying to capture the sentiment of the judges as they evaluate our students' business plans.
Studies shows that VADER performs as good as individual human raters at matching ground truth. Further inspecting the F1 scores (classification accuracy), we see that VADER (0.96) outperforms individual human raters (0.84) at correctly labelling the sentiment of tweets into positive, neutral, or negative classes.3
Now go back to your initial Python project, "businessPlan" for this section.
Add the following script to begin our sentiment analysis.
Start a new frame then click copy text button and paste the contents into the frame.
vader stands for "Valence Aware Dictionary and Sentiment Analysis." It can be used on unsupervised data. Our current data set is labled with the rating 0 or 1 given by each judge for each comment.
the variable "sia" is created by making and instance of the SentimentIntensity Analyzer
There is no output from this script.
Start a new frame then click copy text button and paste the contents into the frame.
Here we are converting the text to numbers
The max features specifies that a maximum of 2000 most occurring words should be use to create the feature dictionary.
The min_df attribute specifies to only include words that appear a minimum of five times.
max_df defines not to include words that occur in more than 70 percent of the document.
There is no output from this script.
Start a new frame then click copy text button and paste the contents into the frame.
Here we are training the dataset on 80% of the data. Twenty percent will make up the X_test file.
There is no output from this script.
Start a new frame then click copy text button and paste the contents into the frame.
Our model is a supervised text classifier model since the dataset contains the judges reviews and their rating 0 for a poor business plan and 1 if they thought it was a good plan.
Using the Random Forest classfier, the training data will learn the relationship between the text review and the rating 0 or 1
There is no output from this script.
Start a new frame then click copy text button and paste the contents into the frame.
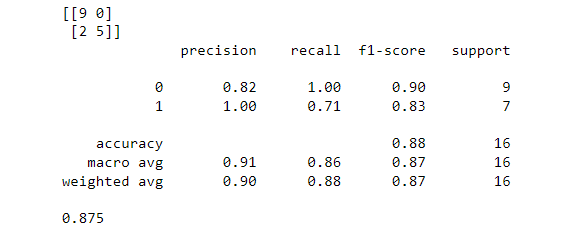
The output is a confusion matrix, classification report and accuracy score.
The confusion matrix, shows 9 true positive and 5 true negative.
The confusion matrix,shows that our model predicted good values and actual good plans were 9.
The confusion matrix show that 5 were actual poor plans and 5 were predicted to be poor plans.
There were 2 false negatives. It is the total counts having prediction is Not a good plan while actually, it was a good plan.
There were no false positives.
Our sample test consisted of 16 reviews (80 times .20). Our model was pretty accurate 14 with correct predictions out of 16, .875.
Making predictions with unseen plan reviews.
Add the following line in a new frame. Here we are going to see if our model can predict a bad review.
print(clf.predict(vectorizer.transform(['The whole plan was poorly done.'])))
Save and run the code. Did you get a [0] for your output indicating that the above text is a negative review?
Now type some positive sounding text, save and run. Did our model predict that this was a postive review?